Statefulness in einer Stateless World: Mein LangGraph Human-in-the-Loop Fail mit FastAPI Workers
Es gibt Fehler, die passieren, weil man den Code nicht versteht. Und es gibt Fehler, die passieren, weil man die Infrastruktur ignoriert. Letztere sind meistens die schmerzhafteren – und genau so einen habe ich mir vor Kurzem mit LangGraph und FastAPI geleistet.
Hier ist die Autopsie eines Bugs, der mich fast in den Wahnsinn getrieben hat, und warum "Works on my Machine" bei LLM-Agenten eine gefährliche Illusion ist.
Das Setup: Human-in-the-Loop
Das Szenario war eigentlich ein Klassiker der modernen LLM-Entwicklung. Ich baute einen Agenten mit LangGraph, der an einem bestimmten Punkt pausieren sollte, um Input von einem Nutzer abzuwarten (Human-in-the-Loop).
Technisch sah das so aus:
LangGraph StateGraph: Ein Workflow mit einem
interrupt_beforeBreakpoint.FastAPI: Als Interface, um den Graphen via REST zu steuern.
Docker: Für das Container-Deployment.
Der Flow: Der Nutzer startet den Prozess $\rightarrow$ Graph läuft bis zum Breakpoint $\rightarrow$ API antwortet "Waiting for Input" $\rightarrow$ Nutzer sendet Input $\rightarrow$ Graph nimmt den State wieder auf und läuft zu Ende.
Lokal auf meinem uvicorn Development-Server (Single Worker) funktionierte das wie ein Uhrwerk. Jeder Test war grün.
Der "Heisenbug" in Production
Dann kam das Deployment. Das Projekt war klein, keine externe Datenbank für LangChain/LangGraph, alles "In-Memory", um Overhead zu sparen. Wir rollten den Container aus und plötzlich passierte das Unbegreifliche:
Der Human-in-the-Loop funktionierte manchmal. Und manchmal bekam ich beim Senden des Nutzer-Inputs einfach einen Fehler, dass die Session/Thread-ID nicht gefunden werden konnte.
Ich verbrachte Stunden mit Debugging. War die thread_id falsch? Hatte ich einen Race Condition im Frontend? Nein. Der Code war identisch zu meiner lokalen Umgebung.
Die Root Cause Analyse: 1 vs. 30
Der Groschen fiel erst, als ich mir das Deployment-Skript genauer ansah. Um Traffic-Peaks abzufangen, wurde FastAPI via Gunicorn/Uvicorn mit ~30 Workern gestartet.
# Das verhängnisvolle Deployment-Kommando (vereinfacht) gunicorn main:app --workers 30 --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000
Und hier liegt das Problem begraben, das jeder Senior Dev eigentlich kennen sollte, aber im Eifer des Gefechts ("ist ja nur ein Container") gerne vergisst:
RAM ist nicht shared zwischen Prozessen.
LangGraph nutzt standardmäßig einen MemorySaver als Checkpointer, wenn nichts anderes konfiguriert ist. Dieser speichert den State des Graphen (die checkpoint Tuple) in einem dict im RAM des Python-Prozesses.
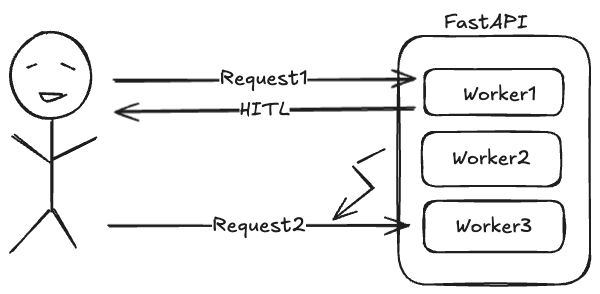
Das passierte in der Realität:
Request A (Start): Landet bei Worker 1. Der Graph läuft, pausiert und speichert den State im RAM von Worker 1 unter
thread_id="abc".User Input: Der Nutzer braucht 10 Sekunden zum Tippen.
Request B (Resume): Der Load Balancer (oder Gunicorn intern) routet den Request an Worker 5.
Crash: Worker 5 schaut in seinen eigenen RAM (
MemorySaver), findet keinethread_id="abc"und wirft einen Fehler.
Da ich lokal nur einen Worker hatte, landeten Start und Resume immer im selben Prozess. In Production war es reines Glücksspiel.
Die Lösung: External Persistence
FastAPI ist per Design stateless. LangGraph mit Human-in-the-Loop ist per Definition stateful. Um diese beiden Welten zu vereinen – und zwar horizontal skalierbar –, muss der State aus dem Python-Heap in eine externe Persistenzschicht wandern.
Die Lösung war trivial, sobald das Problem erkannt war: Wir implementierten einen persistenten Checkpointer.
# Pseudo-Code Lösung
from langgraph.checkpoint.postgres.aio import AsyncPostgresSaver
async with AsyncPostgresSaver.from_conn_string("postgresql://...") as checkpointer:
graph = workflow.compile(checkpointer=checkpointer)
# Jetzt lesen ALLE Worker den State aus der DB
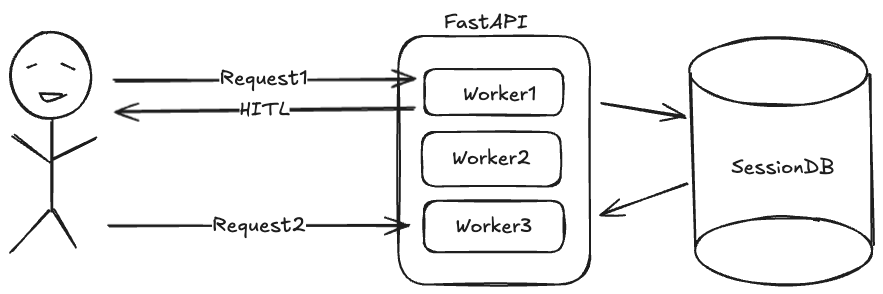
Damit schreibt Worker 1 den State in die DB, und Worker 5 liest ihn beim Resume wieder aus.
Key Takeaways für Lead Devs
Dieser Fail hat mir drei Dinge wieder schmerzhaft ins Gedächtnis gerufen:
DevOps ist auch Dev-Sache: Es reicht nicht, eine funktionierende App zu bauen. Du musst wissen, wie sie ausgeführt wird. Die
WORKERS-Variable in einem Dockerfile oder Kubernetes-Manifest kann deine Architektur fundamental verändern.In-Memory ist Tech Debt:
MemorySaverist toll für Unit Tests oder Jupyter Notebooks. Aber sobald du Human-in-the-Loop oder asynchrone Jobs in Production hast, ist eine Datenbank (Postgres, Redis oder auch deine Vector DB) für das State-Management unumgänglich. Sonst skaliert dein Agent nicht.Annahmen validieren: Ich nahm an: "Ein Container = Eine Instanz". Die Realität war: "Ein Container = 30 isolierte Prozesse". Prüfe die Gegebenheiten, bevor du dich auf Fehlersuche im Business-Logic-Code begibst.
Fazit: Wenn dein Agent ein Gedächtnis braucht, verlass dich nicht auf den RAM. Der vergisst nämlich alles, sobald der Request endet oder der Worker wechselt.