Text-RAG vs. Vision-RAG: Die Architektur-Wahl für moderne Dokumenten-Systeme
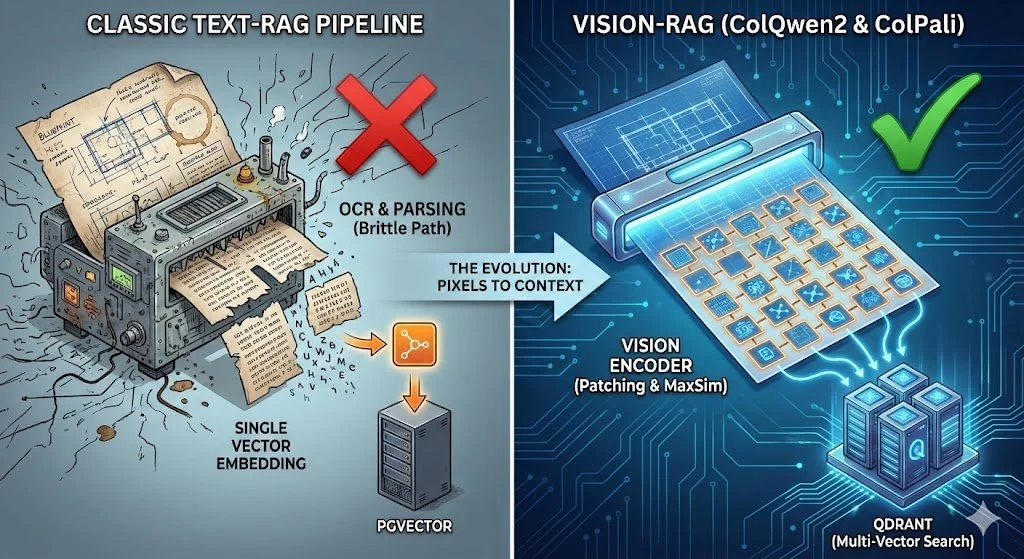
In der Welt der Retrieval Augmented Generation (RAG) gibt es kein "One Size Fits All". Während klassische, textbasierte Pipelines die unangefochtenen Champions für die Verarbeitung von flüssigen Texten, Reports und Büchern sind, hat sich für visuell komplexe Dokumente eine spezialisierte Alternative etabliert: Vision-RAG (basierend auf Modellen wie ColQwen2).
Dieser Artikel beleuchtet beide Ansätze und erklärt, warum die Wahl der Architektur entscheidend für die Qualität Ihrer Informationssuche ist.
Der Goldstandard für Text: Die klassische Pipeline
Für Standard-Dokumente (Word-Dateien, saubere PDFs, Markdown) ist die klassische RAG-Pipeline hocheffizient und kostengünstig.
Der Prozess:
Parsing & OCR: Dokumente werden in reinen Text konvertiert.
Chunking: Der Text wird nach festen Regeln (z.B. 512 Token) zerlegt. Hierbei werden oft Metadaten oder Kontext-Header hinzugefügt.
Single-Vector Embedding: Ein Modell (z.B. OpenAI
text-embedding-3) komprimiert den gesamten Chunk in einen einzigen Vektor.Speicherung: Die Vektoren landen in klassischen Datenbanken wie PGVector, wo sie via Cosine Similarity blitzschnell verglichen werden.
Stärken: Extrem performant bei großen Textmengen, geringer Speicherverbrauch und ausgereifte Tooling-Landschaft.
2. Die Herausforderung: Wenn Layout Information ist
Klassisches RAG stößt an seine Grenzen, wenn die Information nicht im Fließtext, sondern in der Struktur steckt:
Baupläne & Schaltskizzen: Hier sind Linien und räumliche Bezüge wichtiger als Wörter.
Tabellen-Scans: OCR verliert bei komplexen Tabellen (z.B. alte Schreibmaschinen-Auszüge) oft die Zuordnung von Zeile zu Spalte.
Multimodale Inhalte: Lehrbücher, bei denen Grafiken und Text eine untrennbare Einheit bilden.
Hier wird das Dokument zum Bild – und genau hier setzt ColQwen2 an.
3. Die Vision-Alternative: ColQwen2 & ColPali
Vision-basierte Modelle eliminieren die fehleranfällige OCR-Schicht. Das Modell "sieht" die Seite direkt als Bild.
Funktionsweise:
Raster-Zerlegung (Patching): ColQwen2 (basierend auf Qwen2-VL) zerlegt einen Seiten-Screenshot in ein dynamisches Raster. Das Modell erzeugt bis zu 768 Patches pro Seite.
Multi-Vektor Repräsentation: Statt eines einzelnen Vektors pro Seite generiert das Modell für jeden Patch einen eigenen 128-dimensionalen Vektor. Eine Seite ist also eine Matrix aus vielen kleinen Informationseinheiten.
Die Suche via Late Interaction (MaxSim)
Die Suche erfolgt nicht durch einen simplen 1-zu-1-Abgleich. Stattdessen nutzt ColQwen den Late Interaction Mechanismus:
Die Text-Anfrage wird ebenfalls in Token-Vektoren zerlegt.
Für jeden Token der Anfrage wird im Dokument der Patch gesucht, der die höchste Ähnlichkeit aufweist (MaxSim).
Die Summe dieser Max-Werte ergibt den finalen Relevanz-Score.
4. Infrastruktur: Die Wahl der Datenbank
Diese technische Tiefe erfordert spezialisierte Backend-Systeme. Da jede Seite hunderte Vektoren erzeugt, steigt der Speicherbedarf massiv an.
Qdrant: Unterstützt ColPali/ColQwen-Workflows bereits nativ. Durch spezialisierte Indizes und Binary Quantization können die Milliarden von kleinen Patch-Vektoren effizient durchsucht werden.
PGVector: Ist ein exzellentes Werkzeug für klassisches RAG, bietet aber aktuell noch keine native Optimierung für diese Art der Multi-Vector MaxSim-Operationen bei hoher Skalierung.
5. Vergleich: Wann brauche ich was?
Um die richtige Architektur zu wählen, muss man die fundamentalen Unterschiede in der Verarbeitung und Infrastruktur verstehen:
Eingangsdaten und Robustheit: Während die Text-Pipeline auf sauberes OCR angewiesen ist und bei Handschriften oder schlechten Scans oft "halluziniert", ist ColQwen2 extrem robust. Da das Modell direkt auf Pixeln arbeitet, stellen Bildrauschen oder komplexe Layouts kein Hindernis dar. Es "sieht" die Tabelle, anstatt sie mühsam rekonstruieren zu müssen.
Komplexität der Vorverarbeitung: Die klassische Pipeline erfordert aufwendiges Engineering für Parsing, Layout-Erkennung und Chunking-Logik. Bei Vision-RAG entfällt dieser Teil fast komplett; ein einfacher Screenshot der Seite reicht als Input aus. Das spart massiv Entwicklungszeit bei komplexen Dokumententypen.
Infrastruktur und Skalierung: Hier punktet das klassische System. Ein einzelner Vektor pro Textabschnitt ist speichersparend und lässt sich hervorragend in Standard-Datenbanken wie PGVector verarbeiten. ColQwen2 hingegen erzeugt hunderte Vektoren pro Seite. Das erfordert spezialisierte Datenbanken wie Qdrant, die das Multivektor-Modell und die MaxSim-Operation nativ und performant unterstützen. PGVector ist für diese spezifische Art der Suche aktuell (noch) nicht optimiert.
Ressourcenverbrauch: Die textbasierte Suche ist im Betrieb unschlagbar günstig. Vision-Modelle wie ColQwen2 sind zwar im Vergleich zu anderen VLMs klein und effizient, benötigen aber dennoch mehr GPU-Leistung bei der Indizierung und mehr Speicherplatz in der Vektordatenbank.
Fazit: Die richtige Balance finden
Vision-RAG ist kein Ersatz für klassisches RAG, sondern eine andere Herangehensweise. Für textlastige Systeme bleibt die klassische Pipeline aufgrund ihrer Effizienz ungeschlagen. Sobald Ihre Daten jedoch "visuell" werden – wenn Handschriften, schlechte Scans oder komplexe technische Zeichnungen ins Spiel kommen – bietet ColQwen2 eine Robustheit, die mit reiner Textextraktion schlicht nicht erreichbar ist.