Lokale Ausführung von Microsoft Azure PromptFlow mit Ollama: Ein Leitfaden für Entwickler 🚀
Hallo zusammen! Als Freelancer und Softwareentwickler ist es mir wichtig, meinen Kunden innovative Lösungen zu bieten, die nicht nur kosteneffizient sind, sondern auch Datenschutzbedenken bereits während der Entwicklung adressieren. Deshalb habe ich eine lokale Entwicklungsumgebung für Microsoft Azure PromptFlow geschaffen, die keine Kosten verursacht und gleichzeitig die volle Kontrolle über die Daten gewährleistet. Mit ein paar Anpassungen lässt sich diese Lösung auch in der Cloud deployen, ohne auf teure APIs und Modelle kommerzieller Anbieter angewiesen zu sein. Heute zeige ich euch, wie ich das gemacht habe! 💻🧠
Einleitung
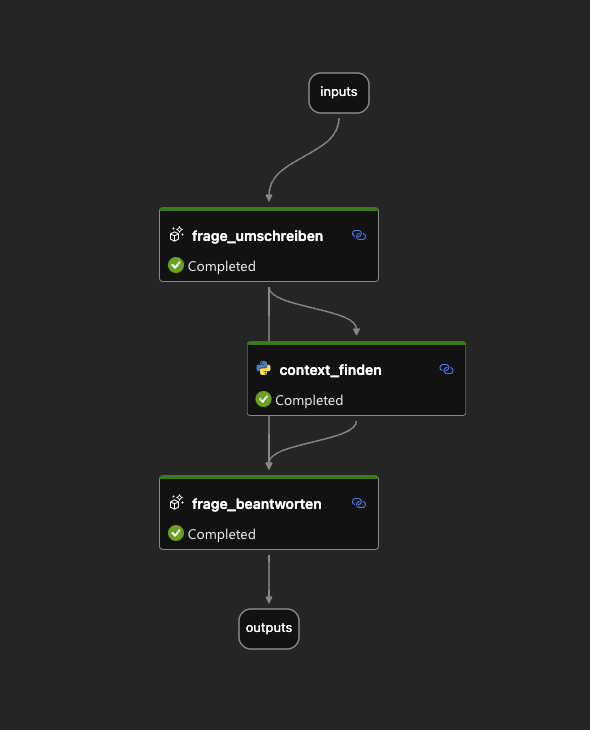
Microsoft Azure PromptFlow ist ein unglaublich mächtiges Tool, um Workflows für große Sprachmodelle (LLMs) zu erstellen und zu verwalten. Es macht den Einsatz von LLMs in verschiedenen Anwendungen und Diensten zum Kinderspiel. Allerdings hat PromptFlow einen kleinen Haken: Es unterstützt standardmäßig keine Ausführung mit Ollama. Aber keine Sorge, ich habe eine Lösung entwickelt, die dieses Problem elegant umgeht! 🛠️
Voraussetzungen
Bevor wir loslegen, solltet ihr bereits mit PromptFlow und Ollama vertraut sein und beide Tools auf eurem System installiert haben. Ein bisschen Python-Kenntnisse sind auch von Vorteil, da wir einen einfachen HTTP-Server implementieren werden. Aber keine Angst, der Code ist überschaubar und leicht nachvollziehbar! 🐍
Der Custom Proxy-Server
Der Star dieses Setups ist ein kleiner Python-Server, der als Proxy zwischen PromptFlow und Ollama fungiert. Er liest eingehende Anfragen im OpenAI-Format, konvertiert sie in das Ollama-Format und leitet sie an die Ollama-API weiter. Hier ist der magische Code:
from http.server import BaseHTTPRequestHandler, HTTPServer
import json
import requests
class OpenAIToOllamaProxy(BaseHTTPRequestHandler):
def do_POST(self):
# Anfrage lesen
content_length = int(self.headers['Content-Length'])
post_data = self.rfile.read(content_length)
openai_request = json.loads(post_data)
# OpenAI-Anfrage in Ollama-Format konvertieren
ollama_request = self.convert_to_ollama_format(openai_request)
# Anfrage an Ollama-API senden
ollama_response = requests.post("http://localhost:11434/v1/chat/completions", json=ollama_request)
# Antwort an den Client senden
self.send_response(ollama_response.status_code)
self.send_header('Content-Type', 'application/json')
self.end_headers()
self.wfile.write(ollama_response.content)
def convert_to_ollama_format(self, openai_request):
# Hier konvertierst du die OpenAI-Anfrage in das Ollama-Format
# Dies ist ein einfaches Beispiel und muss an deine spezifischen Anforderungen angepasst werden
ollama_request = {
"model": "llama3.2:latest",
"messages": openai_request.get("messages", ""),
"max_tokens": openai_request.get("max_tokens", 1000)
}
return ollama_request
def run(server_class=HTTPServer, handler_class=OpenAIToOllamaProxy, port=8080):
server_address = ('', port)
httpd = server_class(server_address, handler_class)
print(f"Starting proxy server on port {port}...")
httpd.serve_forever()
if __name__ == "__main__":
run()
Funktionsweise des Codes
Anfrage lesen: Der Server liest die eingehende POST-Anfrage von PromptFlow.
Konvertierung: Die Anfrage im OpenAI-Format wird in das Ollama-Format konvertiert. Dabei wird das Modell
llama3.2:latesthinzugefügt, das normalerweise in der API-URL enthalten ist.Weiterleitung: Die konvertierte Anfrage wird an die lokale Ollama-API gesendet.
Antwort senden: Die Antwort von Ollama wird zurück an den Client (PromptFlow) gesendet.
Konfiguration in PromptFlow
Um PromptFlow mit unserem Proxy-Server zu verbinden, müssen wir eine Custom Connection in der PromptFlow-Konfiguration anlegen. Hier die Konfiguration:
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/ServerlessConnection.schema.json name: custom_ollama_connection type: serverless api_key: "<no-change>" # Use'<no-change>' to keep original value or '<user-input>' to update it when the application runs. api_base: "http://localhost:8080/"
Erklärung der Konfiguration
name: Ein beliebiger Name für die Verbindung.
type: Der Typ der Verbindung, in diesem Fall
serverless.api_key: Hier wird
<no-change>verwendet, da Ollama keinen API Key benötigtapi_base: Die Basis-URL unseres lokalen Proxy-Servers.
Fazit
Mit diesem Setup könnt ihr Microsoft Azure PromptFlow lokal auf eurem Rechner betreiben und Anfragen an ein Ollama-Modell weiterleiten. Das gibt euch die Freiheit, eure eigenen Modelle zu verwenden und die volle Kontrolle über eure Daten zu behalten. Es ist eine großartige Möglichkeit, eure technischen Fähigkeiten zu erweitern und kreative Lösungen zu entwickeln! 🌟
Ich hoffe, dieser Blog-Post hat euch inspiriert und euch gezeigt, wie einfach es sein kann, coole technische Herausforderungen zu meistern. Wenn ihr Fragen habt oder mehr über meine Arbeit erfahren möchtet, dann schickt mir gerne eine Nachricht auf Linkedin oder schreibt mir direkt über meine Webseite!
Viel Spaß beim Ausprobieren! 🚀💻